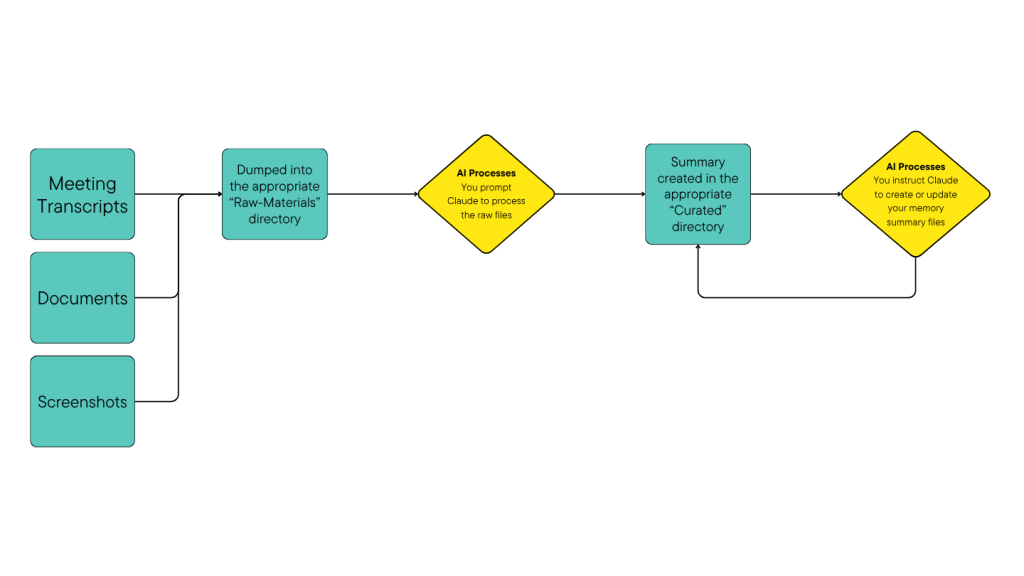
The third-party transcription app I was using for my AI memory system got flagged as non-compliant at work. Zoom’s built-in transcription only really works when you’re the host. For vendor calls, external meetings, and anything where I wasn’t running the show, I needed an alternative that was free, local, and (more) compliant.
So I built one.
The Starting Point: Manual but Functional
I already had OBS Studio installed (it’s on our approved software list) and knew it could record audio. My initial workflow was basic:
- Manually start OBS recording before a meeting
- Stop recording after
- Run OpenAI’s Whisper locally on the audio file
- Paste the transcript into Claude Desktop for summarization
It worked, but had obvious problems:
- Everything was manual
- No speaker separation (just one wall of text)
- Back-to-back meetings meant falling behind on processing
- Easy to forget to start/stop recording
The Evolution: From Manual to Automated
First, I automated the OBS control using its websocket API. No more clicking around in the UI, just command-line control.
Then I realised I could use OBS’s multi-track recording to solve the speaker problem to some extent:
- Track 1: My microphone
- Track 2: Desktop audio (everyone else)
This works perfectly for 1-on-1 meetings, since there are only 2 of you, but for group meetings you’ll only know for sure what was said by you, and everyone else.
Haven’t figured out a way to solve this yet, but to be honest AI summarization does a pretty good job in most cases of inferring who said what. It may just make mistakes in meetings where it’s important to know exactly who said what (e.g. assigning tasks or follow-up actions).
FFmpeg could extract these tracks as separate files, Whisper could transcribe them independently, and a simple Python script could merge them with timestamps:
[00:01:23] Me: What's the status on the inference service?
[00:01:31] Others: Still blocked on GPU allocation...Finally, I opened Cursor (using Gemini 2.5) all my requirements, and asked it to build a proper CLI tool. The result was a bash script that orchestrated everything: OBS control, audio extraction, transcription, and transcript merging.
The Final Tool: Simple Commands, Complete Workflow
bash# Start recording
./run.sh start "Sprint Planning"
# Process all recordings when you have time
./run.sh process
# Check what's queued
./run.sh status
# Discard a recording
./run.sh discardKey features I added during refinement:
- Queue system: Records meeting metadata to
processing_queue.csvfor batch processing later (for when I have several back-to-back meetings and need to be able to process them later) - Automatic stop: Starting a new recording auto-stops the previous one (because I have a crap memory 😉)
- Idempotent processing: Won’t re-process already completed steps if interrupted (e.g. if you start recording a meeting but nobody shows, or you don’t want to process it for some other reason)
- Configurable Whisper models: Trade speed for accuracy based on your needs (I haven’t played with this much, so have only tried the base and small models, which worked well, but there is a turbo model too which looks interesting)
The Technical Stack
Everything runs locally:
- OBS Studio: Multi-track audio recording (already approved in my use)
- FFmpeg: Extract multiple audio tracks from MKV files
- Whisper: Local transcription (base model by default, configurable)
- Python: Controls OBS via websocket, merges SRT files
- Bash: Orchestrates the workflow
Why This Works for Me
- Fully local: No data leaves your machine
- Uses approved tools: in my case at least
- Handles real workflows: Queue system for back-to-back meetings
- Good enough quality: Whisper’s base model is sufficient for most meetings
- Searchable output: Timestamped, speaker-separated transcripts
The transcripts feed directly into my AI assistant for summarization, action item extraction, and long-term context building. No manual notes, no missed decisions, no compliance issues.
Get It Running
The tool is here: https://github.com/dcurlewis/obs-transcriber along with more detailed instructions.
Setup is straightforward:
- Install OBS Studio and enable websocket server
- Install FFmpeg and Python dependencies
- Configure OBS for multi-track recording
- Run the commands
It’s not as polished as commercial services, but it solves my specific problem of local meeting transcription. Improvements I’m already thinking about are:
- auto-deleting the recordings once they’re processed
- cuts down disk space bloat, but importantly reduces the amount of potentially sensitive data lying around
- even auto-generating summaries and deleting the transcripts themselves for a full end-to-end solution
- drop me a comment here (or in Github) if you have any other ideas for improvements
If you’re facing similar constraints – need transcription, can’t use cloud services, don’t control the meetings – this might help. Or inspire you to build your own version.
Disclaimer: I’ve only “tested” this lightly today on a few meetings, so your mileage may vary, and do your own due diligence as always.
Cheers,
Dave