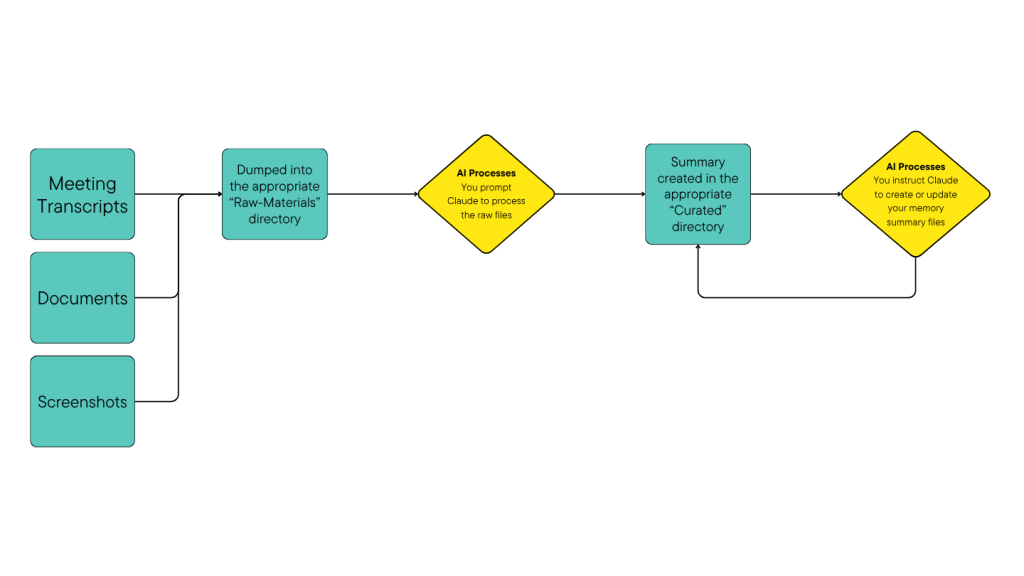
I’ve written about my AI memory system before, which gives Claude a “deeper” memory across conversations. I rely on this every day, but noticed that it still misses some context due to the fact that so many day-to-day conversations happen in Slack.
Stuff like design discussions, technical opinions, those crucial “oh by the way” messages that reshape entire roadmaps, etc.
But Slack is surprisingly lacking in terms of smart data export or analysis. For example, we have an internal helpdesk type of channel which I wanted to get a dump of data from to analyse; things like request count trends, documentation gaps, underserved teams, etc – but no luck, even when I requested this data through proper internal channels (i.e. IT).
Anyway, I needed something that could grab specific conversations, preserve the context, and output clean markdown that my AI assistant could digest. So I built “SlackSnap”. 🎉
Starting Simple-ish
The good old “copy/paste” doesn’t really work here (no threads, messes up formatting, etc), so I didn’t start that simple.
First I tried a javascript snippet that grabbed textContent from message elements. It kinda worked, but:
- Slack’s DOM is a maze of virtual scrolling and dynamic loading, and the last time I pretended to be a “web developer” was in the 90s 🧓
- Only captured visible messages (maybe 20-30 out of hundreds)
- Lost all formatting (code blocks became walls of text)
- No thread support
- Usernames were just IDs like “U01234ABCD”
So I rebuilt it as a proper Chrome extension. This gave me:
- Background service workers for file downloads
- Content scripts with full DOM access
- Storage API for configuration
- Proper permissions for Slack domains
But the real breakthrough came when I discovered Slack loads its API token into localStorage. Instead of scraping the DOM, I could use Slack’s own API (well… *I* didn’t discover shit, the nice AI in Cursor informed me that this might be a better option 😄)
Next: Dual Extraction Methods
SlackSnap uses a two-pronged approach:
Method 1: API-Based Extraction (Primary)
// Get auth token from Slack's localStorage
const config = JSON.parse(localStorage.getItem('localConfig_v2'));
const token = config.teams[teamId].token;
// Fetch messages via conversations.history
const messages = await fetch('/api/conversations.history', {
method: 'POST',
body: new URLSearchParams({
token: token,
channel: channelId,
limit: '100',
oldest: oldestUnix
})
});The API approach is nice and simple (and understandable!) because it:
- Gets ALL messages in the specified time window, not just visible ones
- Includes thread replies with conversations.replies
- Provides consistent data structure
- Works with Slack’s pagination
But the user IDs problem remained. Slack returns messages like:
{
"user": "U123ABC",
"text": "Should we refactor the auth service?",
"ts": "1753160757.123400"
}Smart User Resolution
Instead of fetching ALL workspace users, which the AI did initially, and *I* actually corrected (chalk 1 up for the humans!), SlackSnap:
- Extracts unique user IDs from messages
- Includes @mentions from message text
- Fetches ONLY those specific users
- Builds a lookup map for the export
// Extract user IDs from messages and mentions
const userIds = new Set();
for (const msg of apiMessages) {
if (msg.user) userIds.add(msg.user);
// Extract @mentions like <@U123ABC>
const mentions = msg.text.match(/<@([A-Z0-9]+)>/g);
// ... collect those too
}
// Fetch only needed users (e.g., 15 instead of 5000)
const userMap = await fetchSpecificUsers(Array.from(userIds), token);Method 2: DOM Fallback
If API access fails (permissions, network issues), SlackSnap falls back to enhanced DOM scraping:
// Scroll to load message history
const scrollContainer = document.querySelector('.c-scrollbar__hider');
for (let i = 0; i < 20; i++) {
scrollContainer.scrollTop = 0;
await new Promise(resolve => setTimeout(resolve, 1500));
// Check if new messages loaded
const currentCount = document.querySelectorAll('[role="message"]').length;
// ... break if no new messages after 3 attempts
}This bit never worked as well (still had issues resolving user names, was more inconsistent with the scrolling, etc) so I may just remove it entirely since I’ve found the API method actually works more reliably.
The Output: Clean, Contextual Markdown
SlackSnap produces markdown that preserves the conversation flow:
# SlackSnap Export: #deathstar-review
*Exported: November 28, 2024 10:45 AM*
---
**D.Vader** (Today 9:15 AM):
Team, what's this I hear about an "exhaust port" vulnerability?
**Galen Erso** (Today 9:18 AM):
Nothing to worry about; low sev vulnerability we can patch out later as a fast-follower :thumbsup: :agile:
**Thread Replies:**
- **Grand Moff T**: It's only 2 meters wide right? nobody's getting close enough to even see it! :approved:
- **Emperor P**: Yeah, okay... its just a vent I guess, probably doesn't lead anywhere important in any case. Thanks teamConfiguration
The options page lets you control:
- Download directory: Organizes exports (e.g., downloads/slack-exports/)
- Filename template:
YYYYMMDD-HHmm-{channel}.mdfor chronological sorting - History window: How many days back to export (default: 7) – things get a bit funky if you download too much from a very busy channel
- Thread inclusion: Critical for capturing full context, or to disable if you just want a high level overview
- Timestamps: Full date/time vs. just time
How I use the output
The structured markdown output feeds directly into my AI context system. The way I do this isn’t to capture every single little detailed message, but to export (on a weekly basis) from a few key channels likely to contain important context, then pass all of those exports into Claude at once, asking it to write a single summary file to memory for that week, focusing on team dynamics, key decisions and technical direction, etc.
Then the memory system can take that Slack summary into account when I do my regular “memory updates”. So now when I start a chat in Claude Desktop, it can make use of context from meeting transcripts and documents I’ve provided, plus Slack conversations!
For the week or so I’ve been using it I’ve noticed that it feels a little more accurate, or “connected to reality”, than it did before. YMMV.
The Technical Stack
Everything runs locally in your browser:
- Manifest V3: Modern Chrome extension architecture
- Slack’s Internal API: Already authenticated, just reuse their token
- Chrome Downloads API: Handles subdirectories properly
- Markdown Generation: Preserves code blocks, links, formatting
Installation and Usage
- Clone from GitHub: https://github.com/dcurlewis/slacksnap
- Load as unpacked extension in Chrome
- Click extension icon on any Slack conversation
- Messages export to your Downloads folder
The export captures the entire history (up to your configured limit), not just what’s on screen.
Only tested on Chrome (but should work on Chromium based browsers, or those using the same extension architecture).
Future Enhancements?
- Selective date ranges: Export specific time periods
- Multi-channel export: Batch export related channels
- Search integration: Export search results
- Attachment handling: Download shared files/images
- Export formats: JSON for data analysis, PDF for sharing
But honestly? The current version solves my immediate need so I probably won’t bother adding too many bells and whistles.
Some Observations
Building this revealed some interesting patterns in how we communicate:
- Critical decisions often happen in threads – Main messages lack context
- Code snippets in Slack are surprisingly common – And poorly preserved
- Timestamps matter more than you think – “Yesterday” is ambiguous a day later
- User attribution is crucial – “Someone suggested” vs. “Darth Vader suggested”
Other observations from me, less related to this tool and more on the process of developing it; “Vibe coding” can still be infuriating, but works a lot better IMO if you provide a decent project plan at the outset.
I’ve seen arguments that planning time is better spent “iterating” (vibing?), but I literally spent 2 or 3 minutes prompting another AI to produce my “plan” based on my quickly thrown together requirements and limitations.
This saved probably hours of the AI running me around in circles with “vibey” scope creep, mocked functions it thinks might be handy when you implement this amazing feature one day (that I definitely didn’t ask for), etc.
Get It Running
The tool is here: https://github.com/dcurlewis/slacksnap
It’s intentionally simple – no external dependencies, no build process, just vanilla JavaScript that manipulates Slack’s own data. If you’re feeding an AI assistant with your work context, this might be the missing piece.
Let me know if you find something like this useful, or if you have any feedback/ideas to share.
Cheers,
Dave
P.S. – Yes, I realize I’m slowly building a suite of tools to feed my AI assistant. Not sure what might be up next, yet…