
Right… enough context, let’s cut the shit and get to the good stuff. Here’s my complete AI memory system – the one I use every day to manage engineering teams.
In the previous posts (1, 2), I showed you the background and high-level setup. Now let’s look at what I’ve built on top of that foundation.
The Architecture (It’s Still Simple)
Quick recap:
- Claude Desktop with Project Knowledge
- MCP Desktop Commander for local file R/W access
- Markdown files organised in folders
What’s evolved is the system layer on top – the memory structure, the commands, and the workflows that make this actually useful.
The Instructions
First, we need to set some ground rules. Basically explain to our old-mate Claude how to interpret what we say, what actions to take based on the role it should play given the context of the documents or meeting transcripts provided, etc.
Below is a sample “context management system” instruction doc (just what I called mine, naming isn’t important) to demonstrate the level of detail needed to get started.
ai-context-management-system.md
# AI Context Management System Guide
## Overview
This document instructs how to manage long-term context using a hybrid approach combining file-based storage and Project Knowledge artifacts.
## Directory Structure
/Users/foo/bar/AI-Context/
├── Raw-Materials/ # Incoming stuff
│ ├── Meeting-Transcripts/
│ └── _Archive/ # Processed materials
├── Curated-Context/ # The actual memory
│ ├── Meeting-Insights/
│ ├── Team-Knowledge/
│ ├── Project-Insights/
│ ├── Decision-History/
│ └── Strategic-Documents/
├── Tasks/ # Strategic task tracking
│ └── strategic-tasks.md
├── Prompts/ # System files & memory summaries
│ ├── memory-organization.md
│ ├── memory-strategy.md
│ ├── memory-projects.md
│ ├── memory-decisions.md
│ ├── memory-team-dynamics.md
│ └── memory-relationships.md
└── Templates/ # Reusable formats
## Memory Command Actions - CRITICAL BEHAVIOR
When I use phrases like "commit to memory", "add to memory", or "save this information", this is NOT a request for analysis in chat. These are EXPLICIT instructions to CREATE A NEW FILE in the appropriate subdirectory.
Example: "commit to memory a summary of this meeting"
Expected behavior:
1. Create a new markdown file with proper naming [YYYYMMDD]-Meeting-Summary.md
2. Write the summary content to this file
3. Confirm the file path where content was saved
Never just provide the summary in chat without creating a file.
## Content Curation Workflow
1. **Processing New Information**
- Analyze incoming content for key insights
- Extract actionable items and patterns
- Create structured summaries focusing on decisions and outcomes
- Place in appropriate subdirectory
2. **Meeting Transcripts**
- Create one summary per transcript (never combine)
- Focus on decisions, action items, and strategic insights
- Note participants and context
- Archive original after processing
3. **Quality Standards**
- Use clear headers and bullet points
- Include metadata (date, participants, context)
- Emphasize actionable over exhaustive
- Maintain ~2-3 page maximum per document
## Strategic Task Tracking
When processing any content, actively identify tasks that:
- Have strategic importance or long-term impact
- Span multiple weeks/months
- Have dependencies or blockers
- Might not be captured in regular task systems
Automatically suggest: "Should I add this to strategic tasks?"
## Memory File Management
When updating memory files:
1. Focus on current state, not historical narrative
2. Use status markers: [ACTIVE], [BLOCKED], [RESOLVED]
3. Archive resolved items with reference
4. Maintain target line counts (100-150 lines)
5. Consolidate related items
## Pattern Recognition
Actively look for:
- Repeated themes across different sources
- Contradictions or conflicts in information
- Emerging risks or opportunities
- Connections between seemingly unrelated items
Surface these patterns proactively.This isn’t my actual version because (as you’ll discover yourself) you’ll continue tweaking and adding to it to make it your own over time, and mine is now a bit of a cobbled-together mess in need of a rewrite.
The Workflow
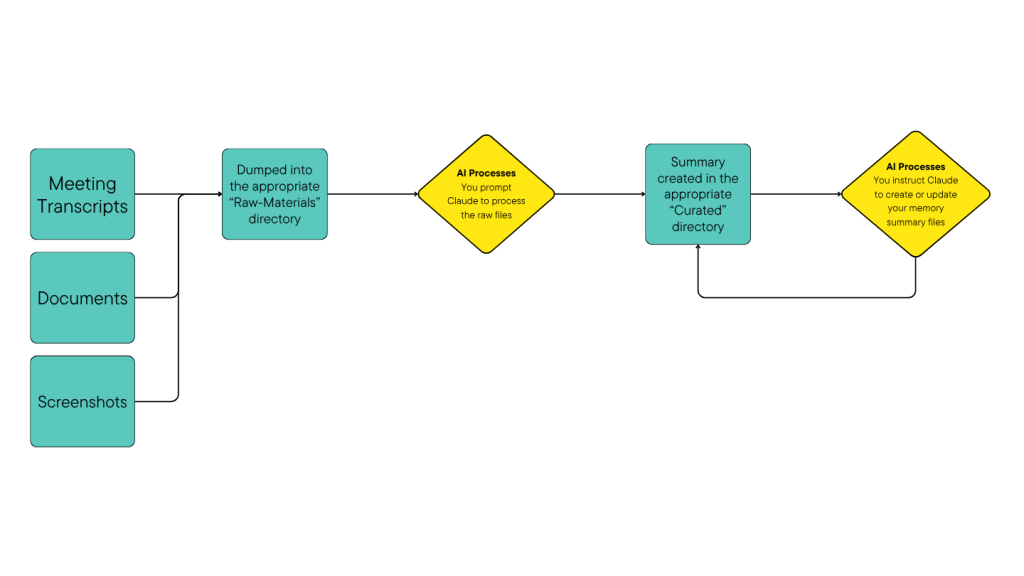
The flow is continuous:
- Raw materials accumulate throughout the day or week
- I process them (using Claude) into structured insights
- Commands consolidate insights into memory files
- Memory files get loaded as Project Knowledge
- Every new chat starts with full context
The Memory Files
After processing, information lives in six core memory files that get loaded into Claude as Project Knowledge:

memory-organization.md
- Current team structure and reporting lines
- Personnel changes and succession planning
- Role transitions and organisational impacts
memory-projects.md
- Active initiatives with status markers
- Dependencies and blockers
- Key milestones and delivery dates
memory-team-dynamics.md
- Team health indicators
- Collaboration patterns
- Morale and engagement signals
memory-strategy.md
- Technical vision and quarterly priorities
- Architecture decisions and tradeoffs
- Strategic initiatives and their rationale
memory-decisions.md
- Pending decisions requiring resolution
- Implementation status of past decisions
- Decision ownership and timelines
memory-relationships.md
- Stakeholder mapping and status
- Cross-functional dependencies
- Vendor and partner relationships
Each file uses status markers: [ACTIVE], [BLOCKED], [CRITICAL], [RESOLVED], [PENDING]
Why Commands Exist
I was already using Claude to update memory files from fairly early on – but I was typing out the full instructions every time:
"Claude, please scan the Curated-Context folder ('/path/to/my_folder') for new files since last Monday (7 April 2025). For each new file, extract relevant information and update the appropriate memory files. For the team dynamics file, focus on current issues and use status markers like [ACTIVE] or [RESOLVED]. Keep each file under 150 lines. Archive any resolved items. Make sure to..."You get the idea. These instructions would run to multiple paragraphs. And despite my best efforts, I’d phrase things slightly differently each time:
- Sometimes I’d say “focus on current state”
- Other times “emphasise active items”
- Sometimes I’d forget to mention the line limit
- Other times I’d use different status markers
So I started saving the prompts to text files, and then I thought to myself “why not just get Claude to read those files?” and my “pseudo-Claude-CLI” file was born.
The Command System
Now here’s what I actually might type as a prompt:
# After each meeting: process the transcript
claude-meeting (brief description of the meeting if you like, but usually not necessary)
# Update memory files with new information (usually each Monday)
claude-memory-scan
claude-memory-update-organization
claude-memory-update-strategy
claude-memory-update-projects
claude-memory-consolidate
# Monday morning: generate my weekly update
claude-monday-update
# Check strategic tasks
claude-tasks
# Prep for upcoming meetings
claude-meeting-prep "stakeholder name"
# Fortnightly: delivery reporting
claude-delivery-scan # uses a Jira MCP to read Jira tickets and report on each goal's progress
claude-delivery-report # Summarizes the above "initial report" into a less detailed, more business user-friendly version for sharing with leadership
Real Workflow: Monday Morning
Here’s my actual Monday routine:
- Update memory files first (10-15 minutes) – This ensures all context from last week is integrated.
claude-memory-scan- Scans for new files added since the last memory update
claude-memory-update-organization,claude-memory-update-strategy,claude-memory-update-projects, etc- Updates each type of memory file with the latest context
claude-memory-consolidate- Moves the updated memory files to the parent directory, archives the previous files, etc.
- I then re-upload these updated memory files into Claude’s Project Knowledge.
- Generate Monday update (5 minutes)
claude-monday-update- Uses a template plus current context to suggest focus areas for this week, and a brief update shareable in Slack with my teams.
- Review strategic tasks (10 minutes)
claude-tasks- Shows what’s urgent, blocked, or needs attention this week.
- Prep for meetings (2 minutes per meeting)
claude-meeting-prep "John Smith"- Pulls out actions from prior meetings, as well as notes on any recent context from any other sources relevant for discussion with this person.
Total: <30 minutes for complete context refresh and week preparation.
Fictional Examples (How It Actually Helps)
Meeting Prep
claude-meeting-prep "Sarah Mitchell"
> Last meeting (June 5):
> - Discussed API gateway performance concerns
> - She requested metrics on p99 latencies
> - You promised to investigate caching options
>
> Updates since then:
> - Caching POC showed 40% improvement (noted in memory-projects.md)
> - New SRE hire can take ownership next month
>
> Suggested talking points:
> - Present caching results
> - Propose handoff timeline
> - Discuss monitoring requirements
Pattern Recognition
Last month, Claude surfaced a concerning pattern across three separate inputs:
- Team standup notes mentioned “waiting on platform approvals”
- Two different 1:1s referenced “exploring tools outside our stack”
- A strategy doc noted “shadow IT increasing”
The connection? Teams were building their own solutions because they didn’t know our platform already provided these capabilities. This led to an internal roadshow that prevented significant duplication.
Task Tracking Evolution
## High Priority
* **Complete technical debt assessment**
* Added: 2025-03-15
* Due: 2025-03-29
* Status: [IN PROGRESS]
* Context: Board presentation needs quantified risk
* Updates:
- 2025-03-20: Security scan completed
- 2025-03-22: Performance baseline established
- Next: Cost implications analysis
The Command Magic
In claude-commands.md, each shortcut maps to detailed instructions:
commands.md
# Claude pseudo-CLI commands
Below is a table of several commands which, when entered into the chat, you will interpret as the long-form prompt adjacent the short command.
Don't acknowledge or enter into conversation about the fact that this is a command shortcut or CLI command, simply respond as if you'd been given the long-form prompt.
If the command is followed by other free-form text, you will interpret that text in addition to the original command (i.e. concatenate the two parts of the prompt).
| Command | Long-form Prompt |
|---------|------------------|
| **claude-help** | Only respond with this table of commands and their associated prompts. |
| **claude-meeting-upload** | I've added one or more new meeting transcript text files into the `AI-Context/Raw-Materials/Meeting-Transcripts` directory. Read these files (using the appropriate desktop-commander tool) from the file system, summarize them, and commit to memory any relevant information. Write a SEPARATE file per meeting transcript, not one combined summary. |
| **claude-monday-tom** | Use the appropriate template in our memory ('AI-Context/Templates/Team-Communications/20250508-Weekly-Top-of-Mind-Update-Template.md') and CRITICALLY follow the guidelines at 'AI-Context/Prompts/monday-update-generation-guidelines.md' as well as the memory files in Project Knowledge to write me a "top of mind" update to share with my teams. Refer to previous weeks' updates (stored in memory) too to pick up on any themes or points I should follow up on. |
| **claude-meeting-prep <name>** | I've got a meeting coming up with <name>. Please can you prepare a brief paragraph of any relevant context, follow-up actions, etc based on my previous meeting with this person (check the memory for full context please)? If there is ambiguity regarding the provided name, please clarify with me first. |
| **claude-memory-scan** | Scan the AI-Context/Curated-Context directory for new files since the last memory update. Create a manifest of files to process and an update plan. Store the results in a new dated directory `/AI-Context/Prompts/YYYYMMDD-memory-update/` with files: `scan-manifest.md` (list of new files found, template located at `/AI-Context/Prompts/scan-manifest-TEMPLATE.md`) and `update-state.json` (tracking progress, template located at `/AI-Context/Prompts/update-state-TEMPLATE.json`). Do not update any memory files yet. |
| **claude-memory-update-organization** | Read the scan manifest from today's memory update directory, then update ONLY the organization & role context. Read the current `/AI-Context/Prompts/memory-organization.md` and create an updated version at `/AI-Context/Prompts/YYYYMMDD-memory-update/memory-organization.md`. IMPORTANT: While updating, consolidate content by: 1) Focusing on current state rather than historical narratives, 2) Using status markers like [IMPLEMENTED], [IN PROGRESS], [PENDING], 3) Moving verbose historical content to archive references, 4) Removing duplication with other memory files, 5) Keeping file concise (target ~100 lines). Update the `update-state.json` to mark this topic as completed. |
| **claude-memory-update-strategy** | Read the scan manifest from today's memory update directory, then update ONLY the strategic direction content. Read the current `/AI-Context/Prompts/memory-strategy.md` and create an updated version at `/AI-Context/Prompts/YYYYMMDD-memory-update/memory-strategy.md`. IMPORTANT: While updating, consolidate content by: 1) Focusing on current state rather than historical narratives, 2) Using status markers like [ACTIVE], [PLANNED], [DEPRECATED], 3) Moving verbose historical content to archive references, 4) Removing duplication with other memory files, 5) Keeping file concise (target ~130 lines). Update the `update-state.json` to mark this topic as completed. |
| **claude-memory-update-projects** | Read the scan manifest from today's memory update directory, then update ONLY the projects & initiatives content. Read the current `/AI-Context/Prompts/memory-projects.md` and create an updated version at `/AI-Context/Prompts/YYYYMMDD-memory-update/memory-projects.md`. IMPORTANT: While updating, consolidate content by: 1) Focusing on active projects with clear status markers, 2) Using markers like [IN PROGRESS], [COMPLETED], [BLOCKED], [PLANNED], 3) Moving completed project details to archive references, 4) Grouping by status rather than chronology, 5) Keeping file concise (target ~120 lines). Update the `update-state.json` to mark this topic as completed. |
| **claude-memory-update-decisions** | Read the scan manifest from today's memory update directory, then update ONLY the decisions & issues content. Read the current `/AI-Context/Prompts/memory-decisions.md` and create an updated version at `/AI-Context/Prompts/YYYYMMDD-memory-update/memory-decisions.md`. IMPORTANT: While updating, consolidate content by: 1) Focusing on active/unresolved decisions only, 2) Using status markers like [IMPLEMENTED], [PENDING], [UNRESOLVED], [STATUS UNKNOWN], 3) Moving implemented decisions to brief summary lines, 4) Grouping by category (Infrastructure, Organizational, Strategic, etc.), 5) Keeping file concise (target ~120 lines). Update the `update-state.json` to mark this topic as completed. |
| **claude-memory-update-team** | Read the scan manifest from today's memory update directory, then update ONLY the team dynamics content. Read the current `/AI-Context/Prompts/memory-team-dynamics.md` and create an updated version at `/AI-Context/Prompts/YYYYMMDD-memory-update/memory-team-dynamics.md`. IMPORTANT: While updating, consolidate content by: 1) Focusing on current dynamics and active issues, 2) Using status markers like [CRITICAL], [MONITORING], [RESOLVED], 3) Removing resolved issues or outdated team dynamics, 4) Consolidating repetitive communication patterns, 5) Keeping file concise (target ~100 lines). Update the `update-state.json` to mark this topic as completed. |
| **claude-memory-update-relationships** | Read the scan manifest from today's memory update directory, then update ONLY the cross-functional relationships content. Read the current `/AI-Context/Prompts/memory-relationships.md` and create an updated version at `/AI-Context/Prompts/YYYYMMDD-memory-update/memory-relationships.md`. IMPORTANT: While updating, consolidate content by: 1) Focusing on active relationships and current status, 2) Using markers like [ACTIVE], [DEPARTING], [BLOCKED], 3) Removing people who have left or outdated vendor relationships, 4) Grouping by relationship type, 5) Keeping file concise (target ~130 lines). Update the `update-state.json` to mark this topic as completed. |
| **claude-memory-consolidate** | Complete the memory update process: 1) Review all updated memory files to ensure consolidation principles were followed (concise, status markers, current state focus), 2) Update memory-index.md with the new update date and summary of changes, 3) Generate a final report showing line count changes and key updates made. Mark the update-state.json as completed. |
| **claude-memory-promote** | After reviewing the updates, promote the new memory files from the dated update directory to the main `/AI-Context/Prompts/` directory, archiving the previous versions to `/Users/dbdave/work/AI-Context/Prompts/_Archive/YYYYMMDD-memory-archived/`. Only run this after you've reviewed the updates. |
| **claude-delivery-scan** | Scan all tracked Jira tickets in `/AI-Context/Delivery-Reports/delivery-tracking.md` for new comments since the last report date. For each ticket, fetch comments and create a summary of updates, highlighting progress, blockers, and key metrics. Store the scan results in a new file `/AI-Context/Delivery-Reports/YYYYMMDD-delivery-scan.md`. |
| **claude-delivery-update <team>** | Update delivery reports for a specific team. Read the tracking file, fetch recent comments for that team's tickets, summarise the updates, and update the 'Last Report' dates in the tracking file. If no team is specified, update all teams. |
| **claude-delivery-report** | Generate a comprehensive delivery report suitable for sharing with leadership. Read the most recent scan results and create a formatted report in `/AI-Context/Delivery-Reports/YYYYMMDD-delivery-report.md` that includes: executive summary, team-by-team progress, key achievements, blockers, upcoming milestones, and metrics. Use the template structure for consistent formatting. |
| **claude-tasks** | Review the strategic task list at `/AI-Context/Tasks/strategic-tasks.md`. Display current tasks organised by priority and status. Check if any tasks need status updates based on recent context. Suggest any new tasks identified from recent meetings or documents. |This lets me maintain consistency without typing reams of instructions.
Important Implementation Details
1. Status Markers Are Useful
Without them, files become append-only history logs. With them, you get:
### Platform Adoption [ACTIVE]
- Shadow solutions emerging in 3 teams
- Internal awareness campaign planned Q2
- Previous evangelism efforts [ARCHIVED - see _Archive/2024-platform-push.md]2. Line Limits Force Priority
Each memory file has a target length. This creates natural pressure to:
- Archive resolved items
- Consolidate related points
- Focus on what matters now
3. Separation Prevents Mess
Raw-Materials/ → unprocessed inputs
Curated-Context/ → processed insights
_Archive/ → historical referenceDon’t mix these.
4. Dating Enables Everything
20250315-Engineering-Sync.md tells Claude:
- When this happened
- Processing order
- Relevance decay over time
Without dates, you have a pile. With dates, you have a timeline.
What This Enables (Real Impact)
Weekly time saved: ~3-5 hours
- No more searching through Slack/email/docs for context
- Meeting prep takes minutes, not half-hours
- Strategic patterns visible immediately
Quality improvements:
- Never miss follow-ups from previous meetings
- Connect decisions across time and teams
- Spot risks before they materialise
Cognitive load reduction:
- Stop holding everything in your head
- Trust the system to surface what matters
- Focus on analysis, not archaeology
The Evolution Path
I didn’t build this overnight. Here’s the rough timeline:
- Week 1-2: Basic file dumping and summaries
- Week 3-4: Realised I needed folder structure and archives
- Month 2: Added status markers when files got unwieldy
- Month 3: Created memory consolidation approach
- Month 4: Built command shortcuts (game changer)
- Month 5: Integrated strategic task tracking
Each addition solved a specific pain point. No grand design, just iterating on friction.
Start Where You Are
- Pick your biggest knowledge pain point
- Create ONE memory file for it
- Feed it information for a week
- Add status markers when it gets unwieldy
- Create shortcuts when you’re tired of typing
The beauty? It’s just text files. You can’t break anything. The worst case is you reorganise some folders.
Next post, I’ll explore what’s missing and where this could go – semantic search, team scaling, integration possibilities. But honestly? Even this simple version has transformed how I work.
What information scattered across your tools would be most valuable if it lived in one place?
Cheers,
Dave
Also in this series:


